1. What is Redshift?
Amazon Redshift is a petabyte-scale cloud data warehouse optimized for OLAP — complex analytical queries across massive datasets.
Core Concept
Redshift = data warehouse. Columnar storage + MPP (massively parallel processing). Leader Node plans queries. Compute Nodes execute. Optimized for BI reports, complex joins, and aggregations on billions of rows.
2. Key Characteristics
- Columnar storage (reads only needed columns)
- MPP: distributed across nodes for parallel execution
- Cluster: Leader Node + Compute Nodes (1–128)
- RA3 nodes (managed storage, recommended), DC2 (local SSD)
- PostgreSQL-compatible SQL
- Scales to petabytes
3. Architecture
Redshift Cluster:
Client → Leader Node (query plan, coordinate)
|
Compute Nodes (1–128, each with slices)
|
Managed Storage (RA3: SSD + S3 tiered)4. Key Features
- Spectrum: Query S3 data from Redshift without loading. Uses Glue Data Catalog. Pay per TB scanned.
- Serverless: No cluster. Auto-provisions. Pay per RPU-second.
- Materialized Views: Pre-computed results. Auto-refresh. Fast repeat queries.
- Concurrency Scaling: Auto-adds capacity during demand spikes. 1 hr free/day.
Data Sharing: Share live data across clusters/accounts without copying.
5. Loading Data

Important Warning
Always use COPY for bulk loading into Redshift, NOT INSERT. COPY is parallel and orders of magnitude faster. Common exam best practice.
6. Athena vs Redshift
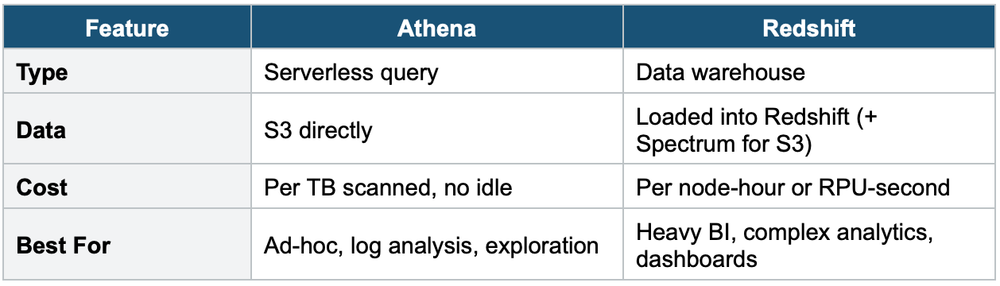
Exam Tip
Redshift: "Data warehouse" = Redshift. "OLAP" = Redshift. "Query S3 from warehouse" = Spectrum. "Bulk load" = COPY command. "Serverless warehouse" = Redshift Serverless. "Ad-hoc SQL on S3" = Athena (not Redshift).