1. What is AWS Glue?
AWS Glue is a fully managed, serverless ETL (Extract, Transform, Load) service. It discovers data, catalogs metadata, and transforms data for analytics and machine learning.
Core Concept
Glue has TWO main functions:
1) Glue Data Catalog: central metadata repository (schema, table definitions, partitions) for your data lake. The "card catalog" for all your data.
2) Glue ETL: serverless Spark-based data transformation jobs. Extract from sources, transform (clean, enrich, convert), and load to destinations.
2. Glue Data Catalog
- Central metadata store for all data assets (S3, RDS, Redshift, DynamoDB, etc.)
- Stores: databases, tables, schemas, partitions, column definitions, data types
- Used by: Athena, Redshift Spectrum, EMR, Lake Formation, Glue ETL jobs
- Apache Hive-compatible metastore (drop-in replacement for Hive Metastore)
- Per account, per Region. Can be shared across accounts via Lake Formation.
Glue Crawlers
- Automatically discover data schemas and populate the Data Catalog
- Crawl: S3 paths, JDBC databases (RDS, Redshift), DynamoDB tables
- Detects: data format (CSV, JSON, Parquet, Avro, ORC), schema, partitions
- Classifiers: built-in (CSV, JSON, Parquet, etc.) or custom (regex, Grok)
- Schedule: run on-demand, hourly, daily, or custom cron
- Output: creates/updates tables in the Glue Data Catalog
Glue Crawler Workflow:
1. Crawler scans S3 bucket: s3://my-data-lake/sales/
2. Detects files: Parquet format, schema: {order_id, product, amount, date}
3. Detects partitions: year=2024/month=01/, year=2024/month=02/
4. Creates a table in the Data Catalog: sales_data
- Columns: order_id (string), product (string), amount (double), date (date)
- Partitions: year, month
- Location: s3://my-data-lake/sales/
5. Athena can now query: SELECT * FROM sales_data WHERE year='2024'3. Glue ETL Jobs
Glue ETL jobs extract data from sources, transform it, and load it into destinations. Jobs run on a serverless Apache Spark engine.
Job Types
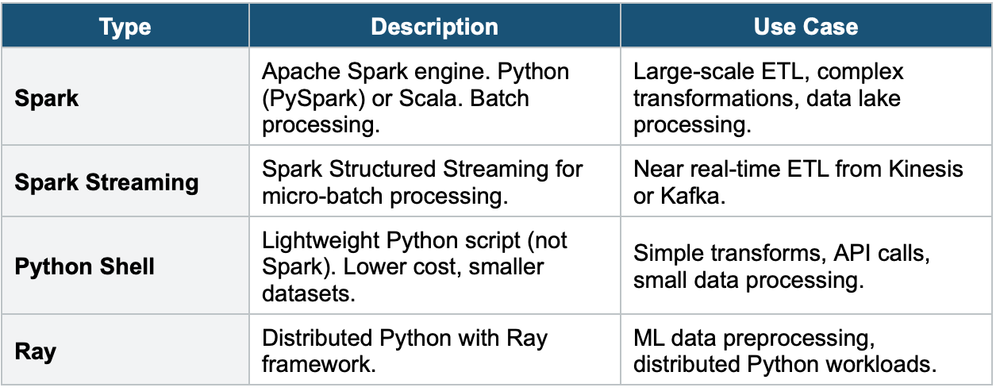
Glue ETL Key Features
- Serverless: no infrastructure to manage. Auto-scales.
- DPU (Data Processing Units): compute units for Spark jobs. You choose the number.
- Visual ETL: drag-and-drop job builder (Glue Studio) — no code required
- Code-based: write PySpark or Scala scripts for full control
- Bookmarks: track which data has been processed (avoid re-processing)
- Job triggers: schedule (cron), on-demand, or event-driven (EventBridge, Glue Workflow)
Glue ETL Sources & Targets

4. Glue Data Quality
- Define data quality rules (completeness, uniqueness, freshness, custom SQL)
- Evaluate rules during ETL jobs or on Data Catalog tables
- Actions on failure: fail the job, log warnings, quarantine bad records
- Use for: ensure data lake data meets quality standards before analytics
5. Glue DataBrew
- Visual data preparation tool (no code)
- 250+ built-in transformations: filter, pivot, join, aggregate, normalize, format
- Profile data: statistics, distributions, missing values, outliers
- Create recipes (reusable transformation sequences)
- Use for: data analysts who need to clean/prepare data without writing code
6. Glue Schema Registry
- Central schema management for streaming data (Kafka, Kinesis, MSK)
- Schema versioning, compatibility checks, auto-registration
- Avro and JSON Schema support
- Producers and consumers validate data against the registered schema
- Prevents: breaking changes from producers, schema drift
7. Glue Elastic Views
- Combine and replicate data across multiple data stores using SQL
- Materialized views that auto-update when source data changes
- Currently supports: DynamoDB as source, S3/Redshift/OpenSearch as targets
Exam Tip
Glue: "Serverless ETL" = Glue ETL. "Data Catalog / metadata store" = Glue Data Catalog. "Auto-discover schemas" = Glue Crawler. "Visual ETL (no code)" = Glue Studio. "Data preparation (no code)" = Glue DataBrew. "Schema management for Kafka" = Glue Schema Registry. Glue Data Catalog is used by Athena, Redshift Spectrum, EMR, Lake Formation. Crawlers populate the catalog.